1.将该文件以utf-8方式保存。<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8" import="java.sql.*,test.DbBean"%>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head><title>test JSP encoding and charset</title></head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<body>
<%
response.setCharacterEncoding ("UTF-8");
out.println("中文");
%>
</body>
</html>
浏览器访问该jsp文件,能正确显示“中文”2字,浏览器设置编码任意非UTF-8,输出乱码。
2.将该文件以ANSI方式保存。
a.浏览器访问该jsp文件,不管怎样设置浏览器编码,均显示乱码。
b.如果将pageencoding改为GBK,其他不变,则浏览器能正确显示“中文”2字,浏览器设置编码任意非UTF-8,输出乱码。
c.如果不改变pageencoding,其他任意改变为gbk,均显示乱码。
d.如果将pageencoding字段删除,更改jsp的contentType的charset为GBK,浏览器能正确显示中文,浏览器设置编码任意非UTF-8,乱码。
3.恢复到最原始文件并以UTF-8保存
a.将response.setCharacterEncoding 改为“GBK”,浏览器能正确显示“中文”2字,浏览器设置编码为任意非简体中文,输出乱码。
b.删除response.setCharacterEncoding 字段,将jsp的contentType的charset为GBK,浏览器能正确显示“中文”2字,浏览器设置编码为任意非简体中文,输出乱码
c.删除response.setCharacterEncoding 以及jsp的contentType,只留下meta的charset,并且为GBK。浏览器能正确显示“中文”2字,浏览器设置编码为任意非简体中文,输出乱码。
d.任意添加一个form,form里有一个文本框club,将方式设置为get,文本框中输入“中文”二字,单击提交,发现如果网页编码(即上述abc)为“UTF-8”,输出为club=%E4%B8%AD%E6%96%87,如果网页编码“GBK”,输出为club=%D6%D0%CE%C4。
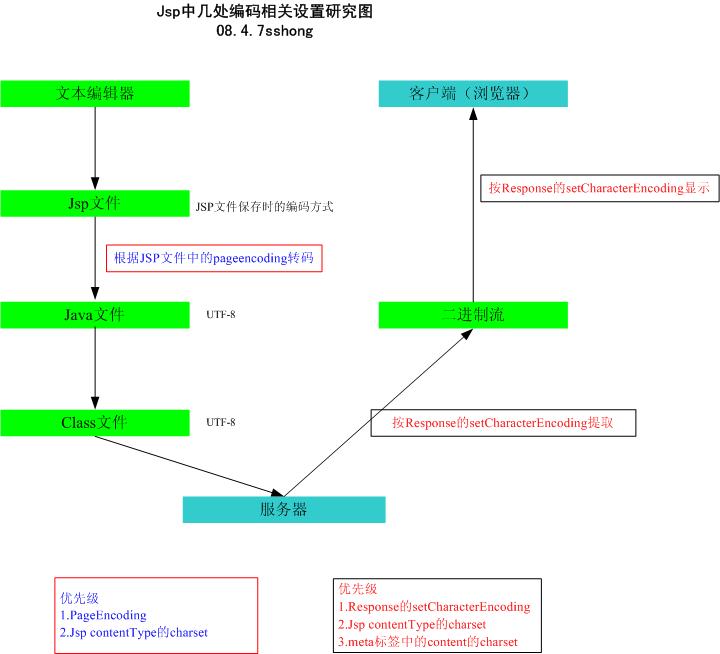
综上,可以看出:
1.pageencoding必须设置成当前jsp文件保存时选择的编码,便于转换为.java,如果这个pageencoding与jsp文件保存时须择的编码不一致,最终无论怎样,肯定出现乱码。
2.没有pageencoding,jsp的contentType的charset可以代替其功能。
3.response的setCharacterEncoding用于告诉服务器以该编码方式提取出class的字节流,并告诉浏览器这些字节流是用该编码的以便正确显示。如果人工修改浏览器编码方式为非改编码,将出现乱码。
4.如果没有setCharacterEncoding字段,jsp的contentType的charset可以代替其功能。
5.如果没有setCharacterEncoding 以及jsp的contentType的charset,html的meta标签中的content的charset可以代替其功能。
6.网页页面中的form将默认采用网页本身(即上述3.4.5)的编码进行参数编码并传递。
结论如下图:
 浙公网安备33010802004887号
浙公网安备33010802004887号